How AI Learns to Read Floor Plans and Plot Maps: Annotation for the Built World
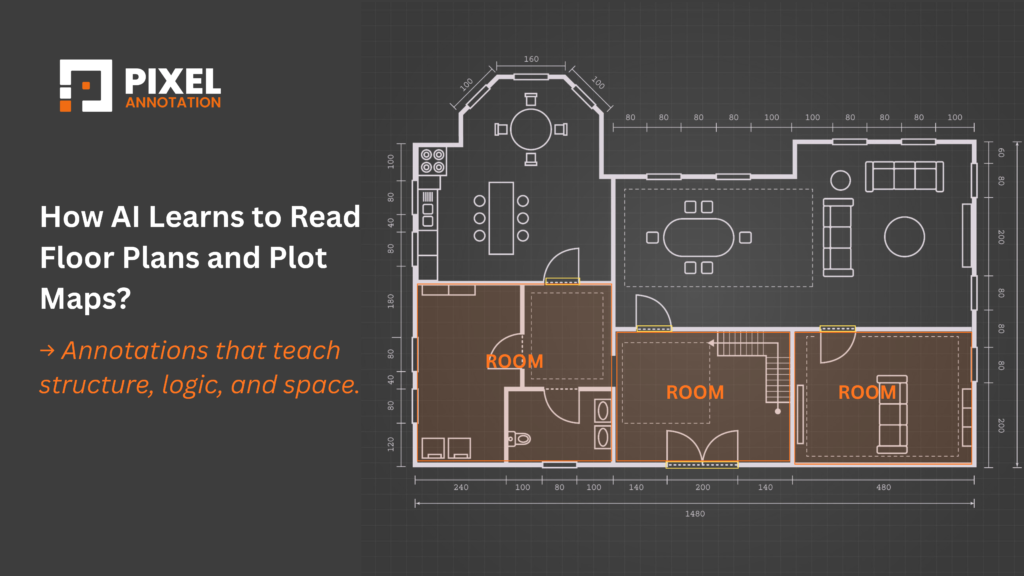
How AI Learns to Read Floor Plans and Plot Maps: Annotation for the Built World Civil drawings are the DNA of the built world but to an untrained machine, they’re just lines on a page. Here’s how expert annotation bridges that gap, and why getting it wrong is not an option. Every civil drawing tells a story of a structure, a system, a space, and the intent behind it. Engineers read that story fluently. Planners, architects, and contractors navigate it daily. But AI? Without structured, expertly labeled training data, it sees nothing more than lines and shapes on a page. This gap between human interpretation and machine understanding is exactly where most AI development in the built environment stalls. And the teams that close it fastest aren’t the ones with the most computing power, they’re the ones with the best training data. Specifically, the ones who got annotation right. Expert annotation is what transforms a static civil drawing into something a machine can reason about. It’s how AI learns the difference between a load-bearing wall and a partition, a setback boundary and a utility line, a structural layer and a mechanical one. Without it, even the most sophisticated model is working blind. Civil Drawings Aren’t Just Images They’re a Language A photograph of a building tells you what something looks like. A civil drawing tells you what something means. That’s a fundamental difference and it’s the core reason AI struggles here without expert guidance. Architectural and civil drawings operate within a highly structured symbolic language. Every element from dashed boundary lines to section markers, hatching patterns to elevation notations carries a specific technical meaning. Meaning that shifts based on context, discipline, regional standard, and drawing type. “To a computer vision model, a load-bearing wall and a partition wall can look identical. To a trained annotator who understands construction, they are completely different objects with entirely different implications.” The variability compounds the challenge further. A notation style common in one state’s zoning department may be unrecognizable to a model trained on another. This isn’t a limitation that better algorithms alone can fix. It requires humans who understand the domain to teach the machine systematically, precisely, and at scale. What AI Actually Needs to Learn from These Drawings Before anyone annotates a single line, it’s worth being clear on what the model needs to understand. Because “reading” a floor plan isn’t one task it’s many, layered on top of each other. A capable AI model for civil drawing interpretation must be able to: None of this is achievable with generic object detection or out-of-the-box computer vision. Each capability requires training data that specifically reflects these distinctions which means annotations built by people who instinctively understand what they’re looking at. The Annotation Toolkit: How We Actually Label These Drawings There’s no single annotation approach that works across all drawing types and use cases. Effective annotation for civil and architectural AI requires a layered, technique-driven strategy. Here’s what that looks like in practice. Bounding Boxes Locating What Matters We use bounding box annotation to identify discrete elements like directional arrows, legend symbols, reference tags, and elevation markers. This forms the foundation for symbol detection models and OCR alignment helping the AI learn to filter out decorative or informational elements from structural ones before deeper analysis begins. Polygon Annotation Defining Spatial Geometry Floor plans demand pixel-perfect precision. Polygon annotations isolate rooms, corridors, balconies, doors, and external boundaries with exact geometry enabling the model to calculate spatial relationships, proximity, and layout logic. These annotations are also the primary input for converting 2D plans into layered 3D BIM-compatible data. Polyline Annotation Mapping Continuous Systems Utility systems don’t exist as isolated objects. Water pipelines, electrical conduits, and fire egress routes run continuously across entire plans. Polyline annotations capture this flow enabling AI to trace pathways, segment zones, and support routing algorithms for both design validation and infrastructure inspection. Custom Ontologies Built for Your Domain No two clients work from identical standards. We collaborate with AI teams to build custom class schemas and annotation taxonomies tailored to specific zoning frameworks, real estate classification systems, or regulatory environments. Your model learns within a logic structure that reflects the domain it will operate in not a generic approximation of it. Why Human Expertise Is Non-Negotiable Here There’s a common assumption in AI development that annotation is a task you can optimize away automate it, crowdsource it, get it “good enough.” In most domains, that works. In civil and architectural drawings, it doesn’t. Domain literacy is irreplaceable. You cannot label what you don’t understand. A dashed line might indicate a setback boundary on a site plan and an overhead soffit on a floor plan. Knowing which requires familiarity with construction conventions not just visual pattern recognition. Context changes meaning. The same symbol carries different meanings across drawing types, project phases, and jurisdictions. Automated tools cannot reliably make these contextual distinctions. Experienced annotators can. Layers must be separated intelligently. Distinguishing a structural element from a mechanical one when they overlap in the same drawing space requires judgment. Mislabeling at this layer cascades into model errors at every downstream task. The stakes are high. A mislabeled access point or misidentified utility line can produce errors in AI-generated permit assessments, compliance checks, or site safety analyses. In this domain, annotation quality directly correlates with real-world risk. “Good annotation in civil drawings doesn’t just label data. It encodes the judgment of experienced professionals into a format that AI can learn from.” Where This Work Gets Applied Real Use Cases Annotated civil drawings aren’t an academic exercise. They’re actively powering real AI applications across some of the fastest-growing sectors in infrastructure and construction technology. Urban Planning & Plot Digitization City governments and planning commissions are using annotated site maps to digitize land records at scale mapping property boundaries, validating zoning compliance, and accelerating the review of construction proposals that previously took weeks to process manually. Construction Monitoring & Compliance By comparing annotated blueprints against as-built photographs,
How AI Learns to Read Floor Plans and Plot Maps: Annotation for the Built World Read Post »