The Data Behind Racket Sports Analytics

Racket sports AI has evolved quickly over the last few years. Not long ago, simply tracking players and generating basic match statistics was considered advanced. Today, expectations are very different. Sports analytics platforms are now trying to understand the game itself, not just observe it.
Coaches want movement analysis. Broadcasters want automated highlights. Performance teams want rally intelligence, shot recognition, and tactical patterns. Players want deeper insights into positioning, footwork, and decision-making.
But while most conversations around sports AI focus on the models, there is another layer that quietly shapes everything the system learns.
The data. More specifically, the annotation behind the data.
Before any AI system can understand a tennis rally, a padel exchange, or a pickleball point, someone has to teach it what those moments actually look like frame by frame. That is where racket sports annotation becomes important.
Why Racket Sports Are So Challenging for AI
To humans, following a rally feels natural. You instinctively understand who is attacking, when momentum shifts, and how the point develops. AI systems do not have that intuition.
For computer vision models, racket sports are one of the hardest environments to understand reliably.
The ball is small and extremely fast. In broadcast footage, it may only appear as a few blurred pixels moving across the frame. Players constantly change direction, overlap each other, and transition between offensive and defensive positions within seconds.
And unlike many other sports, the meaning of the game often exists across sequences rather than individual frames.
A single image rarely explains what is happening.
The AI needs context:
- How the player moved before the shot
- Where the ball came from
- How the rally evolved
- What happened immediately after contact
That is why racket sports analytics depends heavily on structured annotation workflows.
Racket Sports Annotation Is More Than Drawing Boxes
One of the biggest misconceptions around sports annotation is that it only involves placing bounding boxes around players.
In reality, modern racket sports datasets are built from multiple annotation layers working together.
Each layer teaches the AI something different about the game.
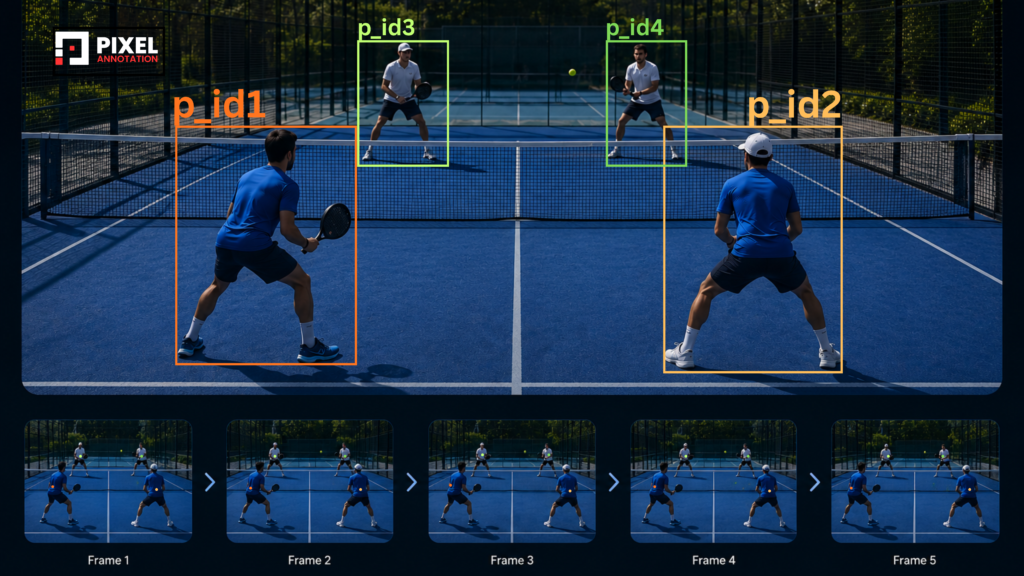
Player Detection and Tracking
he first step is helping the system understand where players are and maintaining that understanding throughout the rally.
That sounds simple until you start working with real gameplay footage.
In tennis singles, the system needs to track two players continuously. In padel doubles, it becomes four players moving rapidly across a smaller court, often crossing positions or partially blocking each other.
And honestly, this is where many datasets quietly fail.
Drawing a bounding box is easy. Maintaining clean player identities through an entire rally is much harder.
If the AI loses track of who is who during a point, every downstream spatial analysis starts becoming unreliable. Positioning data breaks. Movement patterns become inconsistent. Tactical analysis loses context.
Good racket sports annotation is not just about detecting players. It is about maintaining continuity across the entire sequence.
Action Recognition Gives Meaning to the Rally
Tracking movement alone is not enough.
The system also needs to understand what the player is doing.
This is where action recognition becomes critical.
Annotations often include actions such as:
- Serve
- Forehand
- Backhand
- Volley
- Smash
- Lobs
- Drop shots
But in racket sports, action annotation is heavily timing-dependent.
The challenge is not simply labeling the shot correctly. The challenge is teaching the AI exactly when the action begins, when contact happens, and how the movement completes.
Even a few inconsistent frames can change how the model learns the timing signature of a shot. And that becomes especially difficult in fast exchanges.
In pickleball datasets, compact swings during dinking rallies can easily blur together. In padel annotation workflows, wall rebounds and defensive recovery shots create sequences that generic sports pipelines are rarely designed to handle correctly.
This is why racket sports annotation requires contextual understanding, not just visual labeling.

Ball Tracking Is Where Complexity Increases Fast
If there is one area that pushes sports annotation systems to their limits, it is ball tracking.
The ball moves fast, changes direction rapidly, disappears behind players, blends into bright backgrounds, and frequently becomes motion-blurred.
Yet almost every sports analytics system depends on understanding it accurately.
Ball annotation typically involves:
- Frame-by-frame ball tracking
- Trajectory understanding
- Bounce point detection
- Visibility state tracking
And unlike static object detection tasks, annotators often need to infer movement continuity even during partially occluded frames.
This becomes especially important in padel annotation, where wall interactions are part of the game itself. If the system cannot understand bounce behavior off the glass, it struggles to understand the tactical structure of the rally.
Most teams underestimate how difficult this becomes at scale.
Because in racket sports, a missing ball frame is not just a small annotation mistake. It can break the entire trajectory sequence.
Pose Estimation Adds Another Layer of Understanding
Modern racket sports analytics is increasingly moving beyond tracking into biomechanics and movement intelligence.
That is where pose estimation becomes valuable.
By annotating body keypoints across movement sequences, AI systems can begin understanding:
- posture
- footwork
- body orientation
- swing mechanics
- movement efficiency
This creates much deeper opportunities for coaching and performance analysis.
Instead of simply identifying where a player is standing, the system starts understanding how the player moves through the rally.
But pose estimation comes with its own challenges.
The difficulty is not just placing keypoints accurately in a single frame. It is maintaining smooth, consistent motion across hundreds or thousands of frames without introducing instability into the movement data.
Small inconsistencies can create jitter in downstream biomechanics analysis, even when the annotations appear visually correct.
That level of temporal precision matters far more in sports datasets than many teams initially expect, which is why keypoint annotation for pose estimation demands more than visual accuracy, it demands frame-to-frame consistency that holds across the full movement arc, not just the contact moment.

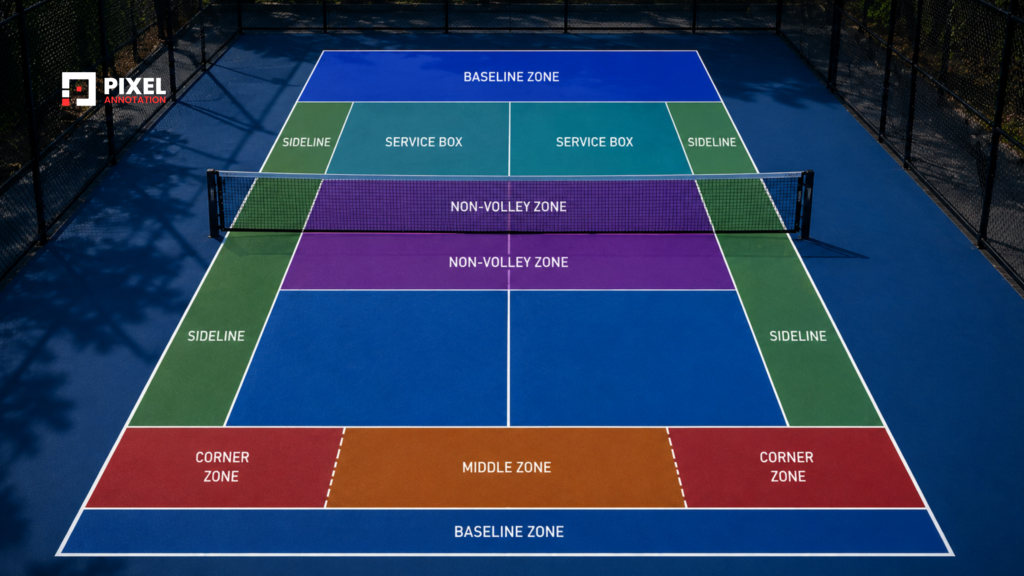
Court Mapping Gives the AI Spatial Understanding
Every movement insight in racket sports analytics depends on spatial context.
The AI needs to understand the court itself before it can understand positioning or tactics.
This includes annotation layers such as:
- Court segmentation
- Line mapping
- Service boxes
- Net regions
- Tactical zones
For pickleball annotation, this also includes the non-volley zone, commonly known as the kitchen. These annotations allow systems to convert raw pixel coordinates into meaningful spatial understanding.
Without that layer, the analytics may still look visually impressive, but the AI lacks real understanding of how players are using the court. And that distinction matters when building serious sports analytics products.
Annotation Quality Quietly Shapes Model Performance
Here is something many teams discover only after training models at scale:
– The model can only learn what the dataset consistently teaches it.
In racket sports analytics, annotation errors rarely stay isolated. A mislabeled action boundary affects shot timing patterns across thousands of examples. An identity switch during a rally corrupts positional understanding for the rest of the sequence. Inconsistent bounce annotations weaken trajectory prediction.
And the difficult part is that many of these problems are not immediately visible. A dataset can appear visually clean while still teaching the AI inconsistent logic.
That is why racket sports annotation requires more than general-purpose labeling workflows.
It requires:
- Sport-specific review
- Temporal consistency checks
- Domain understanding
- Sequence-level quality control
Because the challenge is not simply annotating frames. It is preserving the logic of the game across the entire dataset.
The Future of Racket Sports Analytics
Racket sports analytics is moving fast. Tennis annotation, padel annotation, and pickleball annotation are no longer niche data tasks — they are the foundation of a whole generation of sports AI products being built right now.
The teams that get this right are the ones who treat annotation as a craft, not a commodity. Who understand that frame-level decisions add up into model-level behavior. Who know the game well enough to annotate it correctly.
At Pixel Annotation, that is exactly how we approach sports annotation — with domain focus, temporal precision, and quality systems built for the specific demands of racket sports data.
We have also worked extensively across other sports. If you are building AI for football, our breakdown of football annotation and what it takes to make game analysis smarter is worth a read. And if you want a broader picture of how sports data annotation works across disciplines, we have covered that in depth here.
Building a racket sports dataset? Let’s connect

